Reading notes: Federated Learning with Only Positive Labels
This blog is the reading note for the paper "Federated Learning with Only Positive Labels" by Yu, Felix X., et al. ICML 2020. Broadly speaking, the authors consider learning a multi-class classification model in the federated setting, where each user has access to the positive data associated with only a single class. Specifically, they propose a generic framework namely Federated Averaging with Spreadour (FedAwS), where the server imposes a geometric regularizer after each round to encourage classes to spread-out in the embedding space. They show that FedAwS can almost match the performance of conventional learning both theoretically and empirically.
Introduction
In this work, the authors consider learning a classification model in the federated learning setup, where each user has only access to a single class. Examples of such settings include decentralized training of face recognition models or speaker identification models, where the classifier of the users has sensitive information that cannot be shared with others.
However, conventional federated learning algorithms are not directly applicable to the problem. Training a standard multi-classification model, the loss function encourages two properties: 1. similarity between an instance embedding and the positive class embedding should be as large as possible, and 2. similarity between an instance embedding and the negative class should be as small as possible. Since the user does not has access to negative class embeddings, the latter is not possible. As a result, if we directly use vanilla federated learning, the model will lead to a trivial optimal solution where all instances and classes collapse to a single point in the embedding space since it can only encourage small distances between the instances and their positive classes.
To address this problem, the authors propose Federated Averaging with Spreadout (FedAwS) framework, where in addition to Federated Averaging, the server applies a geometric regularization to make sure that the class embeddings are well separated. Thus when two properties are both encouraged during training, the model would have a comparable performance with the model trained with conventional learning.
Algorithm
To ensure that different class embeddings are separated from each other, the authors propose Federated Averaging with Spreadout (FedAwS). In addition to Federated Average, the server performs an additional optimization step on the class embedding w, which takes the following form (d(.) is a distance measure):

The FedAwS algorithm which modifies the Federated Averaging using the spreadout regularizer is summarized as follow:

The algorithm differs from the conventional Federated Averaging in two ways. First, averaging of W is replaced by updating the class embeddings received from each client (Steps 13). Second, an additional optimization step is performed on the server to encourage the separation of the class embeddings (Step 14).
However, there still remains two challenges when performing optimization in Step 14. First, the threshold is hard to choose, while second when the class number C is large, the computing the regularizer becomes expensive. Thus, here comes the modification:

This regularizer only considers top k classes that are closest to the class c in the embedding space. Instead of choosing a threshold, the regularizer will set it adaptively based on the distance between class c and its (k+1)-th closest class embedding during training.
Experiments
The authors choose square hinge loss with cosine distance to define the loss in Step 8:

which encourages all positive instances and label pairs to have dot product larger than 0.9 in the embedding space.
Here are methods compared in the experiments:
- Baseline-1: Training with only positive squared hinge loss. As expected, it would be very low precision values because the model quickly collapses to a trivial solution.
- Baseline-2: Training with only positive squared hinge loss with the class embeddings fixed. This is a simple way of preventing the class embeddings from collapsing into a single point.
- FedAwS: Proposed method.
- Softmax: An oracle method of regular training with softmax cross-entropy loss function that has access to both positive and negative labels.
 |
| Table 1: Precision@1 (%) on CIFAR-10 and CIFAR-100 |
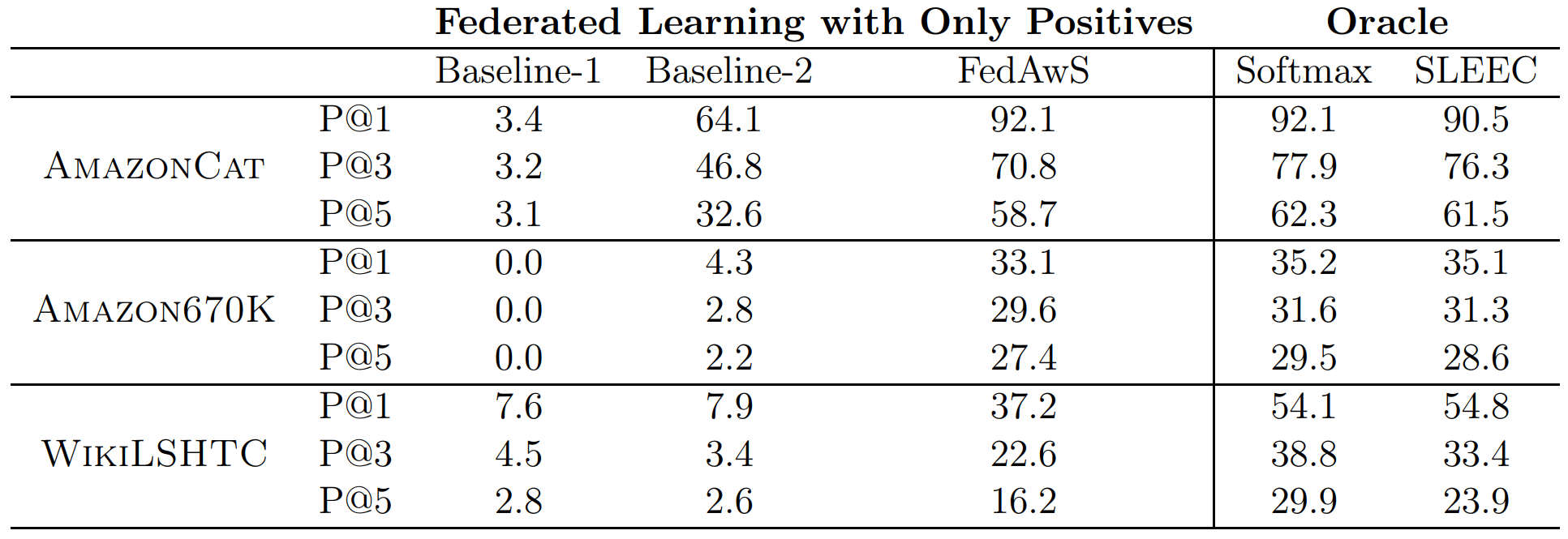 |
| Table 2: P@1,3,5 (%) of different methods on AmazonCat , Amazon670K and WikiLSHTC |
 |
| Table 3: P@1,3,5 (%) of different meta parameters on AmazonCat |
Summary and Reviews
Authors consider a novel problem, federated learning with only positive labels, and proposed a method FedAwS algorithm that can learn a high-quality classification model without negative instance on clients
- The problem formulation is new.
- The author justified the proposed method both theoretically and empirically.
- An extensive experiment with extreme-multiclass settings shows promising results, which is close to regular training.
Cons:
- In practical application, the only positive label setting on each client is very rare. Each client has part of labels that may be more common. The author may address this more realistic setting.
- For the experiment part, it would be better to see the result on the standard image classification such as ImageNet, which has much higher resolution and more classes.
- The pick of one hyper-parameter k is key to influence the performance, which takes time for tuning.
- The class embedding defined in the paper is different from the commonly used class embeddings generated from class-level features, which may confuse the reader.



Comments
Post a Comment