Reading notes: Improving Adversarial Robustness (two papers in ICCV 2019)
This blog is the reading note for the two papers: "Improving Adversarial Robustness via Guided Complement Entropy" by Hao-Yun Chen, et al., ICCV 2019 and "Adversarial Defense by Restricting the Hidden Space of Deep Neural Networks" by Aamir Mustafa, et al. ICCV 2019. Broadly speaking, these two papers deal with the problem of adversarial attacks on natural images. Specifically, the authors of these two papers both design novel training methods that force the network to learn well-separated feature representations of different classes in some manifolds. This ensures that attackers can no longer fool the network within a restricted perturbation budget.
Introduction
Deep neural networks are vulnerable to adversarial attacks, which are intentionally crafted to fool them by adding imperceptibly small perturbation to an input image. Several papers have pointed out that the main reason for the existence of such perturbation is the close proximity of different class samples in the learned feature space. This allows the decision of model to be changed by adding minuscule perturbation. To counter this problem, the author of both papers tries to widen the gap in the manifold between different classes which forces the attacks to use larger perturbation to create successful attacks.
To improve the adversarial robustness via the intuition described in the introduction, the authors propose a new training objective called "Guided Complement Entropy" (GCE). Different from the usual choice of cross-entropy (XE), which focuses on solely optimizing the model's likelihood on the correct class, the GCE adds penalty that suppresses the model's probabilities on incorrect classes. Such formulation helps increase the distance between clusters of different classes. This can be illustrated in Fig 1 where GCE clearly makes the cluster of different classes more separable compare to cross-entropy (XE).
Complement Entropy loss is traduced to facilitate the primary cross-entropy loss during the training. Following equation shows the mathematical formula of the Complement Entropy:
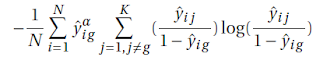
and the notations are summarized in Table 1:
The idea behind the design of the Complement Entropy is to flatten out the distribution among the incorrect classes. Mathematically, the entropy is maximized when all predicted probability on incorrect classes are equal. Under such a situation, the prediction of incorrect classes will be "neutralized" to a small value.
Based on the Complement Entropy, the author propose an enhanced loss called "Guided Complement Entropy", the formula of GCE is shown in the following equation:

The GCE introduces a guiding factor to modulate the effect of complement loss factor during the training iteration. The intuition behind the GCE is that, during training, when the prediction of the true class is low, the model is not yet confident. Thus, the guiding factor reduces the impact of the complement loss factor. On the other hand, as the model gradually improves their performance, the guiding factor will encourage the optimizer to become aggressive on neutralizing the weights on incorrect classes. The log(K-1) is a normalized term based on the number of classes K. With these two improvements, the algorithm can converge to a well0performing model, in terms of both the testing accuracy and the adversarial robustness.
Table 2 shows the main result of the model's robustness towards different attacks. The models trained with GCE always have higher classification accuracy than the baseline models trained with standard XE, under the six white-box adversarial attacks: Fast Gradient Sign Method (FGSM), Basic Iterative Method (BIM), Projected Gradient Descent (PGD), Momentum Iterative Method (MIM), Jacobian-based Saliency Map Attack (JSMA), and Carlini & Wagner (C&W).
Similar to Fig 1, Fig 2 illustrate intuition described in introduction. The feature learnt by the proposed scheme are well separated for different classes and hard to penetrate compared with feature learnt using standard loss. To achieve this goal, the author propose a new loss named "Prototpye Conformity Loss", here is the equation:

x and y are input-label pair i represent different class, f is the feature represented and w is the trainable center, Each class is assigned a fixed and non-overlapping p-norm ball and the training samples belonging to a class i are encouraged to be mapped close to its hyper-ball center. As a result, the overall loss function used for training is given by:

The authors also include deep supervision on different layers of the model by adding an auxiliary branch G(.), which maps the features to a lower dimension output and then used in the overall loss as shown in Fig 3.
My Opinion
Both papers present a novel training method to increase the model adversarial robustness by maxing separation of different classes in some manifolds. The extensive experiments show their method has better performance comparing with the standard training method. However here are some issues may be addressed in the future. 1. Although both papers use the same attack methods to evaluate their model, the settings are varied, even under a similar setting the results of the same baseline are quite different. As a result, it is hard to tell which one is better based on the experiment results, some benchmark datasets are required for the future. 2. Both papers do not evaluate their model on large datasets such as Imagenet. For paper 2, since it learned centroids for different classes, the computational cost will significantly increase with a larger number of classes.
Reference
Chen, Hao-Yun, et al. "Improving Adversarial Robustness via Guided Complement Entropy." arXiv preprint arXiv:1903.09799 (2019).
Mustafa, Aamir, et al. "Adversarial Defense by Restricting the Hidden Space of Deep Neural Networks." arXiv preprint arXiv:1904.00887 (2019).
Introduction
Deep neural networks are vulnerable to adversarial attacks, which are intentionally crafted to fool them by adding imperceptibly small perturbation to an input image. Several papers have pointed out that the main reason for the existence of such perturbation is the close proximity of different class samples in the learned feature space. This allows the decision of model to be changed by adding minuscule perturbation. To counter this problem, the author of both papers tries to widen the gap in the manifold between different classes which forces the attacks to use larger perturbation to create successful attacks.
Methods & Experiments
Paper 1: Improving Adversarial Robustness via Guided Complement Entropy
 |
| Figure 1. latent space of the models trained by different objective functions on CIFAR10. Visualization is done using t-SNE. Left: the model trained with cross-entropy (XE). Right model trained with GCE. Compare to XE, more distinct clusters are formed for different classes from traying with GCE. |
To improve the adversarial robustness via the intuition described in the introduction, the authors propose a new training objective called "Guided Complement Entropy" (GCE). Different from the usual choice of cross-entropy (XE), which focuses on solely optimizing the model's likelihood on the correct class, the GCE adds penalty that suppresses the model's probabilities on incorrect classes. Such formulation helps increase the distance between clusters of different classes. This can be illustrated in Fig 1 where GCE clearly makes the cluster of different classes more separable compare to cross-entropy (XE).
Complement Entropy loss is traduced to facilitate the primary cross-entropy loss during the training. Following equation shows the mathematical formula of the Complement Entropy:

and the notations are summarized in Table 1:
 |
| Table 1. Basic Notations in paper 1. |
The idea behind the design of the Complement Entropy is to flatten out the distribution among the incorrect classes. Mathematically, the entropy is maximized when all predicted probability on incorrect classes are equal. Under such a situation, the prediction of incorrect classes will be "neutralized" to a small value.
Based on the Complement Entropy, the author propose an enhanced loss called "Guided Complement Entropy", the formula of GCE is shown in the following equation:

The GCE introduces a guiding factor to modulate the effect of complement loss factor during the training iteration. The intuition behind the GCE is that, during training, when the prediction of the true class is low, the model is not yet confident. Thus, the guiding factor reduces the impact of the complement loss factor. On the other hand, as the model gradually improves their performance, the guiding factor will encourage the optimizer to become aggressive on neutralizing the weights on incorrect classes. The log(K-1) is a normalized term based on the number of classes K. With these two improvements, the algorithm can converge to a well0performing model, in terms of both the testing accuracy and the adversarial robustness.
Table 2 shows the main result of the model's robustness towards different attacks. The models trained with GCE always have higher classification accuracy than the baseline models trained with standard XE, under the six white-box adversarial attacks: Fast Gradient Sign Method (FGSM), Basic Iterative Method (BIM), Projected Gradient Descent (PGD), Momentum Iterative Method (MIM), Jacobian-based Saliency Map Attack (JSMA), and Carlini & Wagner (C&W).
 |
| Table 2. Performance (%) on white-box adversarial attacks with a wide range of perturbations. The model of MNIST is Lenet-5 and CIFAR 10 is Resnet-56. |
Paper 2: Adversarial Defense by Restricting the Hidden Space of Deep Neural Networks
 |
Figure 2: Latent feature space of a clean image and its adversarial counterpart (PGD attack) for standard SoftMax trained model and proposed method on MNIST (top row) and CIFAR-10 (bottom row) datasets. Note that the proposed method correctly maps the attacked image to its true-class feature space.
|
x and y are input-label pair i represent different class, f is the feature represented and w is the trainable center, Each class is assigned a fixed and non-overlapping p-norm ball and the training samples belonging to a class i are encouraged to be mapped close to its hyper-ball center. As a result, the overall loss function used for training is given by:
The authors also include deep supervision on different layers of the model by adding an auxiliary branch G(.), which maps the features to a lower dimension output and then used in the overall loss as shown in Fig 3.
 |
| Figure 3: An illustration of training with of Lpc and Lce, G(.) is an auxiliary branch for deep supervision. |
Table 3 shows the main results for the different attacks. The model trained with new loss function outperform the basic standard loss function in both White-box and Black-box settings.
 |
| Table 3 Robustness of the model in white-box and black-box settings. |
My Opinion
Both papers present a novel training method to increase the model adversarial robustness by maxing separation of different classes in some manifolds. The extensive experiments show their method has better performance comparing with the standard training method. However here are some issues may be addressed in the future. 1. Although both papers use the same attack methods to evaluate their model, the settings are varied, even under a similar setting the results of the same baseline are quite different. As a result, it is hard to tell which one is better based on the experiment results, some benchmark datasets are required for the future. 2. Both papers do not evaluate their model on large datasets such as Imagenet. For paper 2, since it learned centroids for different classes, the computational cost will significantly increase with a larger number of classes.
Reference
Chen, Hao-Yun, et al. "Improving Adversarial Robustness via Guided Complement Entropy." arXiv preprint arXiv:1903.09799 (2019).
Mustafa, Aamir, et al. "Adversarial Defense by Restricting the Hidden Space of Deep Neural Networks." arXiv preprint arXiv:1904.00887 (2019).
are intentionally crafted to fool image
classification models.



Adversarial robustness is about making models resilient to small, malicious perturbations that can fool predictions. Below is a concise, actionable roadmap covering what to use, how to implement it, and when each method helps.
ReplyDelete1. Understand the Threat Model
Before applying defenses, define:
Attack type: white-box (attacker knows your model) vs black-box
Perturbation budget: how large the change can be (e.g., ϵ in L
∞
)
Goal: untargeted vs targeted misclassification
Common attacks you’ll test against:
Fast Gradient Sign Method (FGSM)
Projected Gradient Descent (PGD)
Carlini & Wagner Attack (C&W)
Deep Neural Network Projects